
| Version | : Candle 0.10 |
| Published date | : Nov 12, 2011 |
error,
duration, type, directory
and map,
are not supported in current beta release).routine,
type,
so that they can be treated as first-class data
as in many functional programming languages; and also the directory
node type, so as to extend the path semantic to the file system level.(d, e) to (a, b,
c) produces
a sequence of cardinality
5: (a b c d e). It does
not produce a sequence
of cardinality
4: (a b c (d e)), such a nested sequence never
occurs.5
as an
integer
is identical to every other instance of the value 5
as an
integer. [Definition: A document order is defined among all the nodes accessible during a given query or transformation. Document order is a total ordering, although the relative order of some nodes is implementation-dependent. Informally, document order is the order in which nodes appear in the serialization of a document.] [Definition: Document order is stable, which means that the relative order of two nodes will not change during the processing of a given query or transformation, even if this order is implementation-dependent.]
Within a tree, document order satisfies the following constraints:
The root node is the first node.
Every node occurs before all of its children and descendants.
Attribute Nodes associated with that element immediately follow the element. The relative order of Attribute Nodes is stable but implementation-dependent.
The relative order of siblings is the order in which they occur in the children property of their parent node.
Children and descendants occur before following siblings.
The relative order of nodes in
distinct trees is stable but
implementation-dependent, subject to the following constraint: If
any node in a given tree, T1,
occurs before any node
in a different tree, T2,
then all nodes in
T1
are before all nodes in T2.
t:003-01-02T11:30:00-05:00'
have several value components in it, (2003, 1, 2, 11, 30, 0.0, -PT05H00M).| Accessor | Prototype | Semantic |
| string-value accessor | ?string
as string |
- returns the string value of the context item; |
| typed-value accessor | ?value
as atomic* |
- returns the atomized value(s) of the context item; |
| qualified-name accessor | ?qname
as qname |
- returns the qualified name of the context item; |
| namespace accessor | ?namespace
as uri |
- returns the
namespace URI of the context item as uri; |
| kind accessor | ?kind
as qname |
- returns the built-in type name of the context item; |
| type-name accessor | ?type
as qname |
- returns the type name of the context item; |
| root node accessor | ?root
as node |
- returns the root node containing the context item; |
| parent node accessor | ?parent
as node |
- returns the parent node containing the context item; |
| previous node accessor | ?previous
as node |
- returns the previous node of the context item; |
| next node accessor | ?next
as node |
- returns the next node of the context item; |
| attributes accessor | ?attributes
as node* |
- returns the attribute nodes of the context item; |
| children accessor | ?children
as node* |
- returns the child nodes of the context item; |
| URI accessor | ?uri
as uri |
- returns the URI that can be used to address the context item; |
| number accessor | ?number
as number |
- returns the numeric value if the type is a numeric type or a measure type; |
| unit accessor | ?unit
as qname |
returns the unit
of a measure as qname; |
| datetime components accessor | ?year,
?month, ?day,
?week-day, ?hour, |
-
returns the
corresponding component of the datetime
type as int; |
| color components accessor | ?r,
?g, ?b as integer |
- returns the r, g,
or b component of a color
as int; |
| source accessor | ?source
as string |
- returns the serialized source text of the context item; |
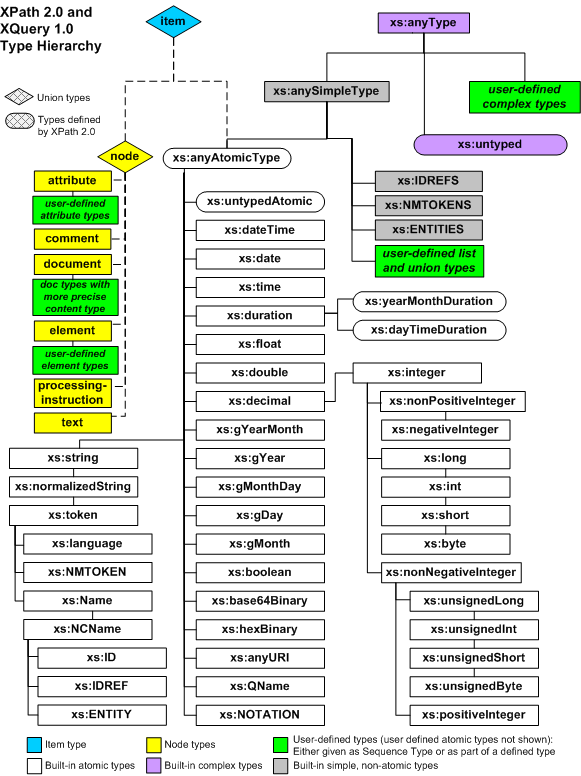
boolean:
same as xs:boolean;byte:
same as xs:byte;ubyte:
same as xs:unsignedByte;short:
same as xs:short;ushort:
same as xs:unsignedShort;int:
same as xs:int;uint:
same as xs:unsignedInt;long:
same as xs:long;ulong:
same as xs:unsignedLong;integer:
same as xs:integer;decimal:
same as xs:decimal;float:
same as xs:float;double:
same as xs:double;string:
same as xs:string;binary:
combines xs:base64Binary and xs:hexBinary;uri:
same as xs:anyURI;qname:
same as xs:QName;id:
same as xs:ID;date-time:
same as xs:dateTime;date:
same as xs:date;time:
same as xs:time;year-month:
same as xs:gYearMonth;year:
same as xs:gYear;month-day:
same as xs:MonthDay;month:
same as xs:gMonth;day:
same as xs:gDay;measure
types: map:
is commonly used
in many scripting languages;directory:
so as to extend
our path semantic to the document
level;xs:untyped:
as Candle is always strong typed,
there's no need for untyped data type in Candle;xs:nonNegativeInteger,
xs:positiveInteger, xs:nonPositiveInteger, xs:negativeInteger,
are not defined
in Candle, as they can be easily implemented as user-defined types in
Candle;xs:IDREF:
is unified under uri
type in Candle;namespace
nodes are treated as pure lexical
information instead of nodes in Candle data model;processing-instruction:
is treated as comment in
Candle;xs:language, xs:ENTITY,
xs:NOTATION, xs:NMTOKEN are
not supported by Candle;